Programování
Principy objektově orientovaného programování (OOP) - třída, objekt, zapouzdření, dědičnost, polymorfismus.
- Třída - blueprint/vzor, podle kterého pak vytváříme instance. Definujeme vlastnosti a chování.
- Objekt - jedna instance nějaké třídy.
- Zapouzdření - veškeré informace, které nejsou potřebné pro klienty modulů, by měly zůstat skryté. (Když chci řídit auto, stačí mi vědět, že musím otáčet volantem a šlapat plyn, nepotřebuju vědět, jak přesně to funguje).
- Dědičnost - založení nové třídy na základě již existující třídy. Základem je rozšíření původní třídy o nové vlastnosti.
- Polymorfismus - možnost tříd vystupovat v jiné roli. Např. když mám třídy sjednocené interfacem, můžu pak do nějaké funce jako parametr dát ten interface a fci používat se všemi třídami, které ten interface implementují.
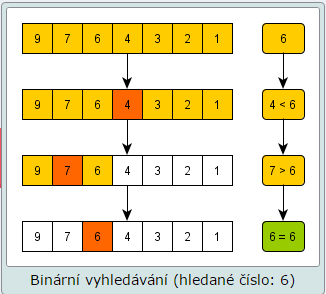
Algoritmy vyhledávání v poli – sekvenční, půlením intervalu, neformální objasnění jejich složitosti.
- Pole musí být seřazené.
- Vezmu prvek, který vyhledávám a porovnám ho s prostředním prvkem v poli.
- Podle toho, jestli je větší nebo menší, tak vyhledávaný prvek musí nutně být v jedné z polovin nebo vůbec.
- Takhle to pole půlím do té doby, než najdu prvek, který hledám.
- Jelikož v každém kroku půlim pole a tou špatnou půlkou se vůbec nezabývám, tak se jedná o složitost log2(n).
Algoritmy třídění – klasifikace, popis činnosti, neformální objasnění složitosti vybraných algoritmů.
-
Vnitřní
- Všechna data uložena v operační paměti a algoritmus k nim může libovolně přistupovat.
- Ne všechna data jsou v paměti, nějaká část může být uložena na disku. V případě, že máme moc dat.
Vnější
-
Klasifikace algoritmů dle chování:
-
Řazení výběrem
-
Selection sort
- V poli najdeme největší prvek a přesuneme na začátek.
- Tento prvek "vyřadíme" a hledáme nejvyšší prvek ve zbylém poli.
- Opakujeme dokud není pole sestupně seřazené.
- Složitost n^2
-
Selection sort
-
Řazení vkládáním
-
Insertion sort
- Přesouvá prvky na správné místo.
- Takhle jdeme postupně od začátku pole až do konce a hledáme, kam ho správně zařadit.
- Animation hier mein respektierung
- Ačkoliv je složitost n^2, tak u téměř seřazeného pole se blíží n. U polí s méně než 10 prvky je rychlejší než quick sort.
-
Insertion sort
-
Řazení záměnou
-
Bubble sort
- Porovnáva dva sousední prvky. Pokud je ten vlevo menší, tak je prohodí a postupuje dál. --> "probublává na povrch"
- Vnitřní cyklus se provede (n-1) + (n-2) + (n-3) +.... = (n^2 - n)/2 což je složitost n^2
-
Heapsort
- Základem je binární halda, jejíž základní vlastností je, že se chová jako prioritní fronta. Pokud z prioritní fronty postupně odebíráme prvky, tak je zřejmé, že tím dochází k jejich řazení.
-
Quicksort
- V poli zvolíme libovolný prvek tzv. pivot.
- Pole přeorganizujeme tak, aby na na jedné straně byly prvky větší a na druhé menší, než pivot.
- Tento postup opakujeme pro obě rozdělené strany, dokud nedojdeme k polím o velikosti 1.
- Při špatné volbě pivota (nejvyšší nebo nejnižší prvek) tak je složitost n^2, jelikož nedochází k dělení pole. Očekávaná složitost při správně volbě pivota je však n*logn
-
Bubble sort
- Řazení slučováním
-
Merge sort
- Pracuje na bázi DVOU už sestupně setřízených polí. Říkejme jim A a B, a pak pole C, které bude to nové mergnuté pole.
- Na vstupu je jedno pole, které merge sort sám rekurzivně dělí a sestupně seřadí.
- V každém kroku porovnáme první prvky a ten vyšší přesuneme na konec nového pole C.
- Tento postup opakujeme tak dlouho, dokud se jedno z polí nevyprázdní a pak ještě přesuneme zbytek toho pole do výsledného pole C.
-
Merge sort
Datové struktury – pole, seznam, fronta, zásobník, strom, graf.
- Indexováno od 0.
- Problém s dynamickou alokací v některých jazycích - nutnost používat pointery.
- Je však jednoduché a tím pádem i rychlé, protože prvky jsou v paměti uloženy zasebou, zabírají všechny stejně místa a rychle se k nim přistupuje.
- Jednotlivé prvky obsahují i ukazatel(referenci) na následující prvek. Poslední prvek ukazuje na NULL
- U obousměrného seznamu ukazatel(referenci) i na předcházející prvek. Posledni ukazuje na další NULL. První okazuje na předcházející NULL
- Prvky se odebírají v pořadí v jakém přisli - FIFO (First In First Out)
- Většinou funkce - Put a Get. Dále ukazatele na první a poslední prvek (Head, Tail)
- Prvky se odebírají v opačném pořadí - LIFO (Last In First Out)
- Většinou funkce - Push a Pop. Dále ukazatele na první prvek - Top
- Každý prvek má nejvýše jednoho předchůdce a může mít víc než jednoho následníka.
- Je tvořen uzly
- Kořen - uzel bez předchůdce
- List - uzel bez následníka
- Vnitřní uzly - klasické uzly, které nejsou ani listem ani kořenem
- Podle maximálního počtu potomů rozlišujeme stromy
- Unární (Seznam)
- Binární
- Ternární
- Prvky menší než kořen se řadí doleva, prvky větší doprava.
- Jedná se o uzly, hrany a incidence. Incidence přiřazuje dvoum uzlům nějakou hranu.
- Neorinetovaný graf - hraně je přiřazená neuspořádaná dvojice uzlů.
- Orientovaný graf - hraně je přiřazena uspořádaná dvojize uzlů.
Rekurze – ukázky rekurzívních algoritmů, složitost, metody odstranění rekurze.
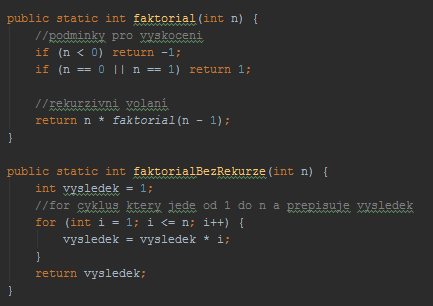
- V tomto případě se jendá o složitost O(n), protože poběží n-krát.
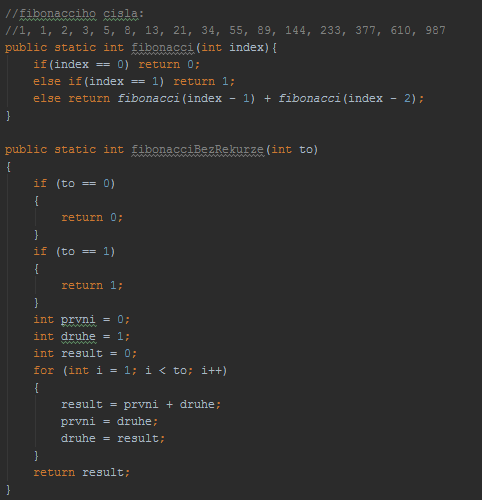
- Posloupnost přirozených čísel, kde každé další číslo je součtem dvou předchozích.
- Často řešeno neefektivní rekurzivní metodou.
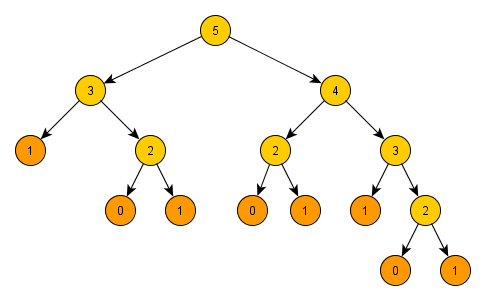
- Při této rekurzivní metodě ovšem dochází k velice neefektivnímu počítání O(2^n) a níže vidíme, že např. pro posloupnost n=5 hodnotu 3 počítáme 2x, hodnotu 2 počítáme 3x a na triviální hodnoty (0,1) se podíváme dokonce 8x
- Odstranění v tomto případě můžeme provést:
- For cyklem, viz. kód.
- Využitím dynamického programování - vypočítané hodnoty si uchovávat v nějaké kolekci a místo počítání hodnot, které už vypočítané máme, je pouze vytáhnout z této kolekce. Tímto stáhneme složitost z O(2^n) na O(n).
- Většinou lze nahradit for cyklem.
- Ušetříme čas za volání funkce včetně předávání parametrů
- Pro cyklus může překladač uplatňovat optimalizace (predikce podmínky), kdežto pro rekurzivní volání ne.
- Rekurze se ukládá na zásobník, pro každou volanou funkci se vytvoří záznam, obsahující informace a parametry.
- Po jejím skončení se tento záznam odebere ze zásobníku a postoupí na další.
- Ne vždy můžeme rekurzi nahradit cyklem. Co ale funguje vždy je nahrazení rekurze vlastním zásobníkem. Na defaultní zásobník se totiž ukládá více informací, než je v některých případech potřeba.
Stromové datové struktury – binární strom, B-strom, popis algoritmů, objasnění složitosti vybraných algoritmů.
- Skládá se z kořene a vnitřních a koncových uzlů. = Root, node, leaf.
- Konkrétní stromy mají většinou definovaný maximální počet potomků - binární, ternární, B-strom (ten má maximálně N potomků).
- Obsahují podstromy - na každý vnitřní uzel se můžeme samostatně dívat jako na kořen vlastního ministromečku.
- Vlastnosti:
- Výška - maximáulní hloubka/úroveň stromu
- Šířka - počet uzlů na jedné úrovni
- Cesta - posloupnost uzlů od kořene k hledanému uzlu
- Délka cesty - počet hran cesty (počet uzlů posloupnosti - 1)
- Vyváženost - pro všechny listy platí, že nejsou o moc* hlouběji, než kterékoliv jiné listy. Nebo jinak - hloubka podstromů se liší max o x*.
- * - přesné číslo se liší v závislostech na konkrétni implementaci, ale většinou se jedná o 1.
- Procházení stromu
- Do šířky - procházení po úrovních
-
Do výšky/hloubky - začne se v kořenu a jde se na potomka. Pokud narazíme na list nebo už byla noda navštívena, vracíme se.
-
Podle pořadí určujeme 3 základní metody.
- Preorder - kořen -> levý podstrom -> pravý podstrom
- Inorder - levý podstrom -> kořen -> pravý podstrom
- Postorder - levý podstrom -> pravý podstrom -> kořen
- Každý uzel má 0-2 potomky.
- Každý uzel právě jednoho rodiče. Vyjímka samozřejmě kořen.
- Uzly obsahují nějaký klíč, podle kterého se vyhledává. Klíče menší než kořen do levého podstromu, klíče větší než kořen do pravého podstormu.
- Efektivní sortování a vyhledávání. U vyvážených stromů se jedná o O(log_n). Proto je důležité mít vyvážený strom.
- Implementace:
- Dynamická struktura, tj. data a reference na levého a pravého potomka. Nevýhoda je, že máme časté ukazatele na null, když nemáme potomky a plýtváme tak paměti.
- Pomocí pole - využíváme implicitních datových struktur (tj. data structure that uses very little memory besides the actual data elements)
- Kořen má nejvýše N potomků. Resp 2-N.
- Vnitřní uzly jsou half-full, tedy mají N/2 až N potomků.
- Všechny listy jsou na stejné úrovni.
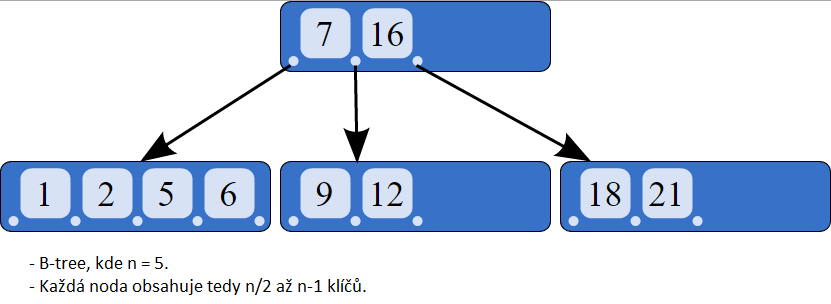
- Vyhledávání je jednoduché, prostě to čislo porovnáváš a správně postupujes.
- Insert více méně to samé, ale při přetečení té nody se musí splitnout a prostřední element jde do předka.
Implementace OOP v programovacích jazycích – popis, srovnání.
- C++ dovoluje třídě dědit z vícero tříd, Java jen z jedné
- Java obsahuje interfacy - můžeme implementovat více interfejsů a jakoby napodobit vícenásobnou dědičnost ale bezpečněji
- C++ může mít oddělené metody (program musí mít main a pak je jedno kde jsou ostatní metody), v Javě všechny metody přísluší třídě.
- Java is Pure OOL so is C#, c++ is mixture of OOL and structured language, so is python.
- C++ statické typy, Java a c# podporují generiky (dynamické typy)
- Některé jazyky umožňují lehce měnit třídy (i za běhu?)
- Java programátora nutí vše programovat jako OOP - všechny třídy dědí z třídy Object
- Práce s objekty v paměti - destructor vs. Garbage Collector
- v C++ Class neco = Objekt; v Jave Class neco = reference
- c++ reference jsou rebindable c*++; v Jave jsou vzdy "statické" (nelze dělat aritmetiku)
- C# vs java = overloadovani operatoru v C#, lepsi exception handling v c# a dalsi co se daji najit v why is c# the best.eu aka MSDN
- C++ ma pointery, c# ma delegata, java suší :(
Java technologie, .NET technologie.
- Java je díky JVM nezávislá na platformě (OS). Byte-code samotný je nezávislý na platformě, ale pro každou platformu existuje vlastní JVM.
- Java compiler převadí source code na Java byte-code, který slouží pro JVM.
- Java Runtime Environment (JRE), doplňující JVM o just-in-time (JIT) compiler, který převádí bytecode na nativní strojový kód.
- JRE dále obsahuje Class Libraries - vzhledem k nezávislosti na platformě, nemůže spoléhat na knihovny OS, tak má vlastní na vše možné.
- Tohle vše je obsaženo v JDK - Java Developement Kit
- Java ME (Micro Edition)
- Java SE (Standard edition)
- Java EE (Enterprise edition)
- Java FX
- Liší se především v knihovnách a různých balíčcích (SE - defines basic types and objects of the Java programming language to high-level classes that are used for networking, security, database access, graphical user interface (GUI) development, and XML parsing) a jejich využití.
- Java ME slouží pro aplikace na zařízeních s omezenými zdroji (memory, display) jako mobily, smart TV, herní konzole.
- Java EE rozšiřuje SE o funkce pro rozsáhlejší IS a jiné podnikové aplikace založené na více-vrstvé architektuře.
- Soubor technologií pro web, Windows a mobilní zařízení
- Standardizovaná specifikace jádra se nazývá Common Language Infrastructure (CLI)
- Podobně jako u Javy lze platformu dělit dle zaměření na
- .NET Micro Framework - pro embedded zařízení
- .NET Compact Framework - pro mobilní zařízení
- .NET Framework - pro stolní PC
- .NET podporuje více jazyků, všechny jazyky se překladačem přeloží do univerzálního kódu pro CLI
- Nejčastější jazyky jsou C#, Visual Basic .NET, Object Pascal; můžeme se setkat i s F#, J#, C++,...
- ASP.NET - Technologie pro vývoj webových aplikací
- WCF - Windows Communication Foundation - technologie pro vývoj webových služeb a komunikační infrastruktury (API)
- WPF - Windows Presentation Foundation - technologie pro GUI
- LINQ - zajišťuje objektový přístup k datům v DB, XML a IEnumerable objektech
- CLI - definuje základní platformu pro architekturu .NET
- CLR - Common Language Runtime - runtime pro .NET
- CLS - Common Language Specification - společný jazyk pro .NET
- CIL - Common Intermediate Language, dříve MSIL
- Assembly - kus Intermediate kódu, který je určen ke spuštění CLR
- JIT - Just In Time kompilace
- GC - Garbage Collector - čistí paměť
- CTS - Common Type System - společné datové jednotky pro všechny jazyky
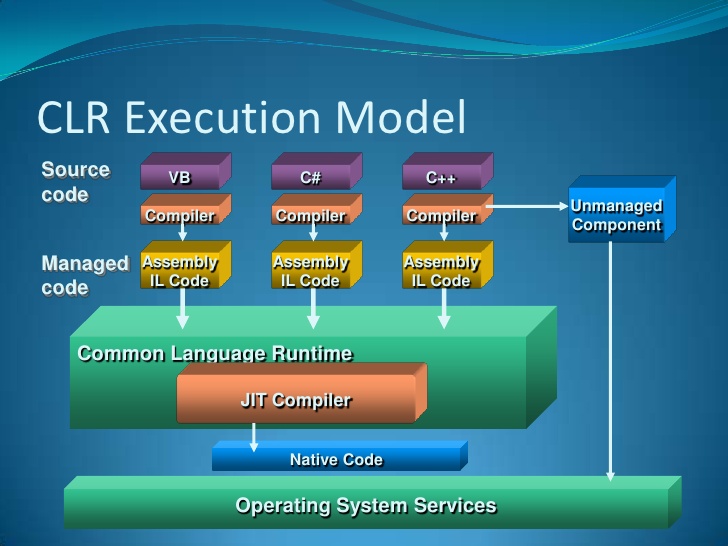
- Zdrojový kód je převeden do CIL.
- CIL je pak převeden do bajtkódu a je vytvořeno .NET assembly.
- Po provedení .NET assembly, jeho bajtkód projde skrz provozní JIT kompilátor, aby generoval nativní kód.
- Nativní kód je zpracováván pomocí procesoru.
Skriptovací jazyky
- Interpretovaný jazyk (nekompilovaný zdrojový kód + interpretor)
- Není třeba deklarovat proměnné
- Dynamická typová kontrola = automatický převod mezi řetězci, logickými hodnotami a čísly
- Pokročilé datové typy, zotavení z chyb co neústí v ukončení skriptu, a další...
Program zapsaný ve skriptovacím jazyce se označuje jako skript. Typicky skript těží z výhody, že se nemusí překládat, a často tvoří rozšiřitelnou (parametrickou) část nějakého softwarového projektu, která se může měnit, aniž by bylo potřeba pokaždé rekompilovat hlavní spustitelný soubor. Skripty proto najdeme u her, složitějších softwarových řešení nebo jako hlavní součást dynamických internetových stránek a podobně. Některé programovacíjazyky mají možnost kompilace do strojového kódu i interpretace; jiné umožňují i mezistupeň, předkompilování do vnitřního jazyka, jehož vykonávání je rychlejší než klasická interpretace.
Typičtí zástupci = PHP, Perl, Python, Ruby, JavaScript, Lua
Některé jazyky mohou být interpretovány i kompilovány - např. Python. Některé jazyky zase mohou obsahovat nějaký mezistupeň (předkompilace) - V8 engine u Chromu předkompiluje Javascript soubory.
- Není potřeba kompilovat -> rychlá změna, možnost sloužit jako přídavek k hlavnímu kompilovanému programu
- Snadnější údržba, vývoj i správa, (testování)
- Možná intepretace kódu z řetězce za běhu
- Netypovost
- Není potřeba kompilovat -> nutně pomalejší než předkompilovaný program
- Netypovost -> větší složitost kódu při ověřování správnosti proměnných, větší chybovost
- Vyšší paměťová náročnost a horší přístup do paměti (větší integritní omezení)